Hu Zhenyu's Blog
访客计数:
about
CUDA 编程模型
怎么样才能让代码在GPU上运行呢? CUDA已经提供了一个很方便的编程环境,编程者只需要掌握了标准的C语言编程,再了解一下GPU编程的特点就可以写出能在GPU上运行的程序了,这里我用一个很简单的程序作为例子。
第一个CUDA程序
#include <stdio.h>
#define ITEM_COUNT 100
__global__ void add(int *a, int *b, int *c)
{
int idx = threadIdx.x;
c[idx] = a[idx] + b[idx];
}
int main(int argc, char **argv)
{
int h_array_a[ITEM_COUNT] = {0};
int h_array_b[ITEM_COUNT] = {0};
int h_array_c[ITEM_COUNT] = {0};
int *d_array_a = NULL;
int *d_array_b = NULL;
int *d_array_c = NULL;
for (int i = 0; i < ITEM_COUNT; ++i) {
h_array_a[i] = i;
h_array_b[i] = i;
}
memset(h_array_c, 0, ITEM_COUNT * sizeof(int));
cudaMalloc(&d_array_a, ITEM_COUNT * sizeof(int));
cudaMalloc(&d_array_b, ITEM_COUNT * sizeof(int));
cudaMalloc(&d_array_c, ITEM_COUNT * sizeof(int));
cudaMemcpy(d_array_a, h_array_a, ITEM_COUNT * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_array_b, h_array_b, ITEM_COUNT * sizeof(int), cudaMemcpyHostToDevice);
cudaMemset(d_array_c, 0, ITEM_COUNT * sizeof(int));
add<<<1, ITEM_COUNT>>>(d_array_a, d_array_b, d_array_c);
cudaThreadSynchronize();
cudaMemcpy(h_array_c, d_array_c, ITEM_COUNT * sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(d_array_a);
cudaFree(d_array_b);
cudaFree(d_array_c);
for (int i = 0; i < ITEM_COUNT; ++i) {
printf("result[%d]=%d\n", i, h_array_c[i]);
}
return 0;
}从上面的程序可以看出来,CUDA的程序和一般的C语言程序并没有什么很大的区别。
一个CUDA程序的基本结构可以分为两个部分。
- 在CPU上运行的 Host 程序。
- 在GPU上运行的 Device 程序。
GPU上运行的函数又被叫做kernel函数。
一个典型的GPU程序的执行流程如下所示:
1. CPU调用GPU编程环境的函数在GPU上分配内存。
2. CPU将输入数据复制到GPU上。
3. CPU讲核函数载入GPU, GPU执行核函数处理数据。
4. CPU将计算的结果从GPU复制回CPU。
为什么需要第2步和第4步呢? 因为一般来说CPU和GPU并没有共享内存(也有共享内存空间的CPU和GPU架构,比如PS4游戏机就是这样的)。
+-------------+ coprocessor +---------------+
| CPU | <-------------> | GPU |
+-------------+ +---------------+
^ ^
| |
| |
v V
+-------------+ +---------------+
| Host Memory | | Device Memory |
+-------------+ +---------------+
不过CUDA 4.0之后就提供了一个统一内存寻址的方式,也就是CUDA帮你搞定数据内存的拷贝,以后学习到那部分再说。
我们这第一个CUDA程序实现了什么功能呢? 就是计算了100个数的相加。如果我们不使用GPU编程计算100个数的相加,程序可以这样写:
#include <stdio.h>
#define ITEM_COUNT 100
void add(int *a, int *b, int *c)
{
for (int i = 0; i < ITEM_COUNT; ++i) {
c[i] = a[i] + b[i];
}
}
int main(int argc, char *argv[])
{
int array_a[ITEM_COUNT] = {0};
int array_b[ITEM_COUNT] = {0};
int array_c[ITEM_COUNT] = {0};
for (int i = 0; i < ITEM_COUNT; ++i) {
array_a[i] = i;
array_b[i] = i;
}
memset(array_c, 0, ITEM_COUNT);
add(array_a, array_b, array_c);
return 0;
}可以看出来CPU版本是用了一个循环来计算100个数的相加,而GPU版本是使用了100个线程(Thread)来计算100个数的相加,每个核函数中可以通过 threadIdx.x 获得当前线程的线程ID, 也就是类似于CPU中的循环变量。启动线程的数量则是通过调用核函数时传递进去的 。
add<<<1, ITEM_COUNT>>>(d_array_a, d_array_b, d_array_c);
线程层次 (Thread Hierarchy)
实际上 threadIdx 是一个三元素的向量,所以线程可以使用1维、2维、3维的 线程索引(thread index), 线程可以组织为三个层次 Grid、Block、Thread。
每个块(Block)所能包含的线程(Thread)数量是有限制的,因为目前每个块内的所有线程都是在一个物理的处理器核中,并且共享了这个核有限的内存资源。当前的GPU中,每个块最多能执行1024个线程。
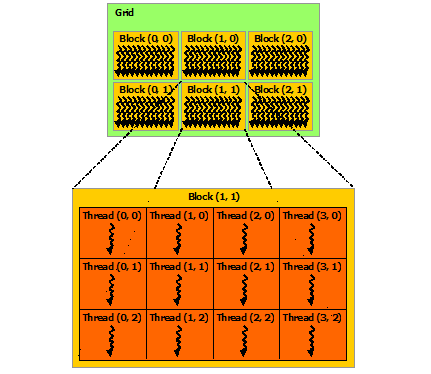
通过 CUDA拓展的 «<…»> 语法我们可以指定运行kernel函数时使用的 每块线程数(The number of threads per block) 和每格块数 (The number of blocks per grid)。
内存层次 (Thread Hierarchy)
CUDA线程中可以寻址不同的内存空间,如下图所示。
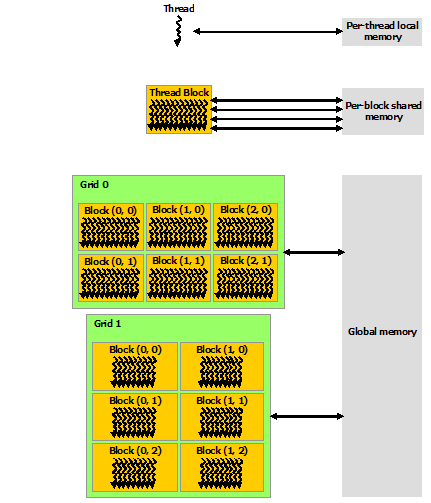
每个线程有自己的本地内存,每个线程块中有共享内存,最外层是全局内存。
不同的内存访问速度如下:
本地内存 > 共享内存 > 全局内存
通过 cudaMalloc 分配的内存就是全局内存。 核函数中用__shared__修饰的变量就是共享内存。 核函数定义的变量使用的就是本地内存。
参考文献

本站采用 知识共享署名-非商业性使用-相同方式共享3.0 中国大陆许可协议 进行许可,转载请注明出处。
推荐使用 chrome 浏览器浏览本站。